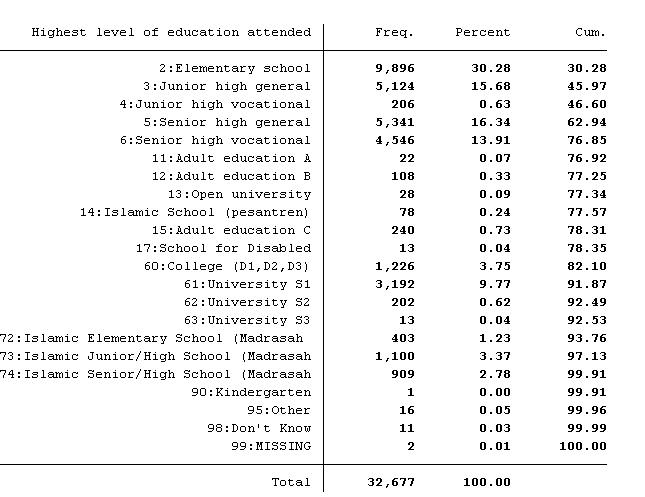
Tabulasi silang (cross-tabulation) adalah proses membandingkan dua atau lebih variabel dalam sebuah tabel dengan memperlihatkan frekuensi atau persentase nilai dari variabel tersebut di setiap kategori. Stata adalah program statistik yang sering digunakan untuk analisis data, termasuk untuk membuat tabulasi silang. Berikut adalah langkah-langkah untuk melakukan tabulasi silang di Stata:
- Buka program Stata dan buka file data yang ingin dianalisis.
- Gunakan perintah “tabulate” diikuti dengan nama variabel yang ingin dianalisis. Misalnya, jika Anda ingin menganalisis hubungan antara jenis kelamin dan tingkat pendidikan, gunakan perintah “tabulate gender education”.
- Jika ingin melihat persentase dalam tabulasi silang, tambahkan opsi “row” atau “col” untuk menunjukkan apakah persentase ingin ditampilkan pada baris atau kolom tabel. Misalnya, jika ingin melihat persentase dari setiap jenis kelamin pada setiap tingkat pendidikan, gunakan perintah “tabulate gender education, row”.
- Jika ingin menggabungkan dua variabel menjadi satu, gunakan operator “&” atau “/” dalam perintah tabulasi silang. Misalnya, jika ingin menganalisis hubungan antara jenis kelamin dan status pernikahan, gunakan perintah “tabulate gender & marital_status” atau “tabulate gender/marital_status”.
- Jika ingin menambahkan opsi lain seperti “missing” atau “chi-square”, tambahkan opsi tersebut setelah perintah “tabulate”. Misalnya, jika ingin melihat frekuensi nilai yang hilang dalam tabulasi silang, gunakan perintah “tabulate gender education, missing”.
- Setelah memasukkan perintah, tekan enter untuk menampilkan tabel tabulasi silang.
Dengan melakukan tabulasi silang di Stata, Anda dapat memperoleh pemahaman yang lebih baik tentang hubungan antara variabel dalam dataset Anda dan membantu Anda mengambil keputusan yang lebih baik berdasarkan hasil analisis data.
Baik uji homogenitas antar group atau uji independensi antar 2 Var.
hipotesis nya
- Ada kesamaan proporsi antar kelompok
- Ada hubungan antar 2 variabel (baris dan kolom).
demikian
salam pembelajar
Salam statistik.